








使用「Requests」+「bs4」写亚马逊爬虫
终于我们还是讲到用「Python」来爬数据了。有些卖家就问了,为什么要用pytho?之前不是已经有一些Chrome插件或者其他简便的方法了吗?是的没错,但是他们都还达不到指哪儿爬哪儿、无惧目标网站封杀的水平呀。
作为已经成为最受欢迎的程序设计语言之一「Python」,它除了具有丰富和强大的库之外,还被赋予“胶水语言”的昵称,毕竟它能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。用它来写爬虫我们就是「站在巨人的肩膀上」,很多东西并不需要我们写,只需要库里拿过来用就行了。
话不多说,接下来小编就来叫大家如何操作!
一、安装Python:
在这里我们使用python 3.6.6版本,可在下面连接中直接下载。
Windows 版本:
https://www.python.org/ftp/python/3.6.6/python-3.6.6.exe
MacOS版本:
https://www.python.org/ftp/python/3.6.6/python-3.6.6-macosx10.9.pkg
其他版本请访问python官网:
https://www.python.org/downloads/release/python-366/
首先将「Add Python 3.6 to PATH」勾选上,点击「Customize installation」。
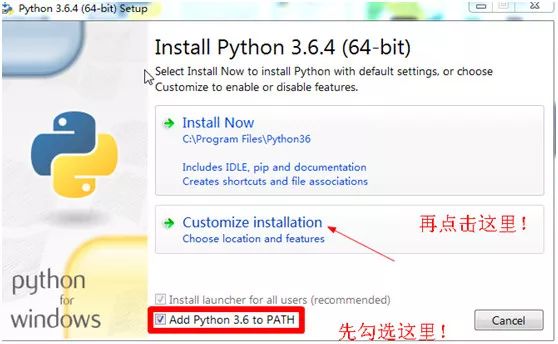
在将「Install for all users」勾选上,点击「install」。

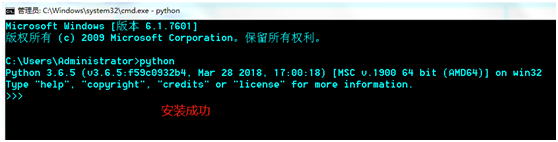
安装完成后,我们来检查一下Python是否安装成功,打开cmd命令,输入python回车,若显示类似下图,证明环Python安装成功。
二、安装PyCharm:
PyChram是一款提供Python开发环境的应用程序,可以帮助我们更好的编写、调试代码。
Windows版本:
https://download.jetbrains.com/python/pycharm-professional-2018.2.exe
MacOS版本:
https://download.jetbrains.com/python/pycharm-professional-2018.2.dmg
具体安装步骤可参考:
https://www.cnblogs.com/dcpeng/p/9031405.html
下载完成后双击打开Pychram安装包,傻瓜化安装,基本一路next。
三、配置PyCharm:
打开pycharm,按下列图片完成配置。
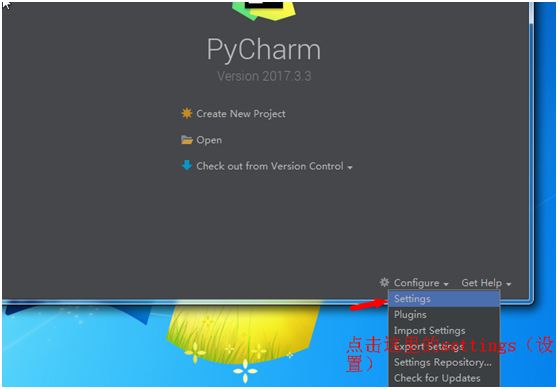
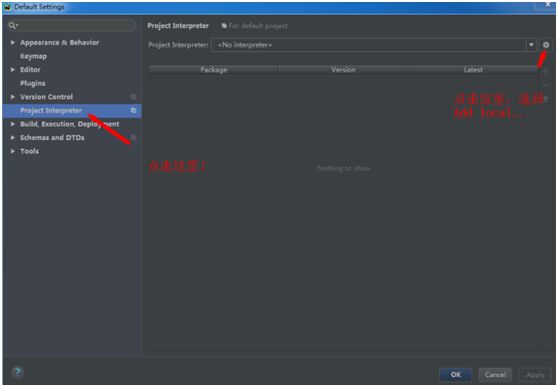
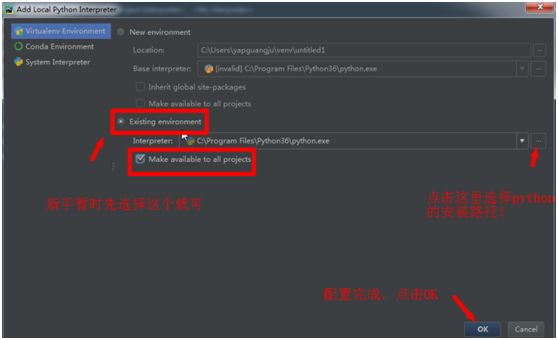
四、创建新项目

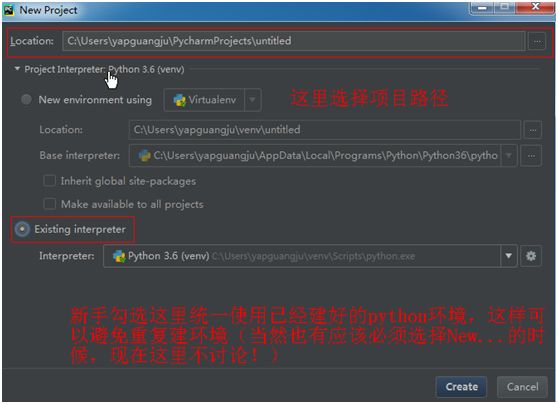
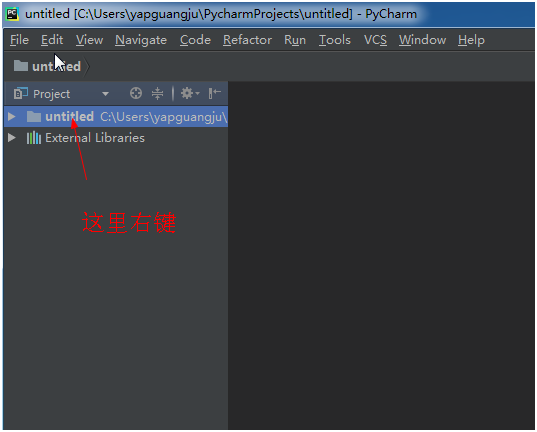

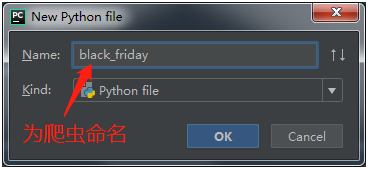
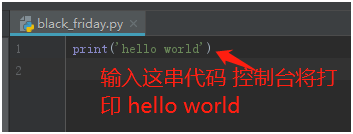
以上就是PyCharm + Python3.6环境的搭建步骤。
爬虫技术需要循序渐进,今天我们先爬一些简单的东西来方便大家理解,为后期爬取亚马逊数据做准备。
分析目标网站
今天我们选择的目标网站是【亚马逊美国站】https://www.amazon.com。首先我们使用Chrome浏览器打开该网站,搜索关键字「iphone」并分析该网站的网页结构。
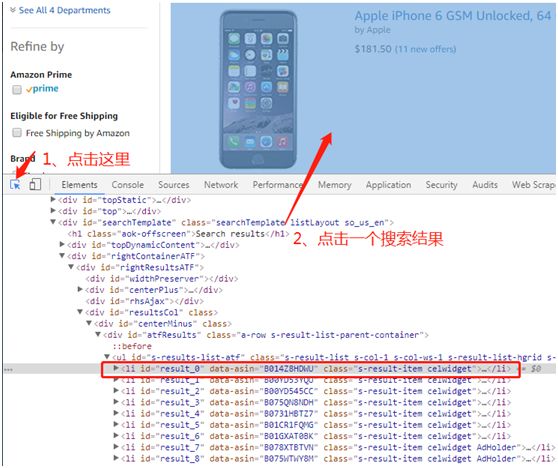
分析后不难看出该网站目标数据处的网页结构:
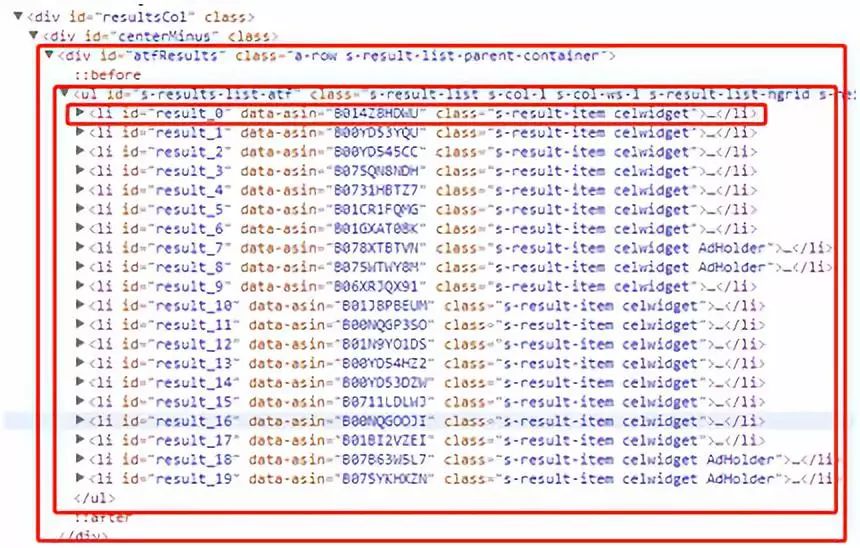
id为s-results-list-atf的<ul>标签包含有数个<li>标签,每一个<li>标签包含了每件商品的一些信息。因此我们只需要请求网页数据,拿到id为s-results-list-atf的<ul>标签源码,然后自己解析、取出自己想要的数据即可。
一、请求数据:
首先我们安装python中的「Requests」。
在我们刚才创建的「black_Friday」中 输入:
import requests # 导入requests
from bs4 import BeautifulSoup # 从bs4中导入BeautifulSoup 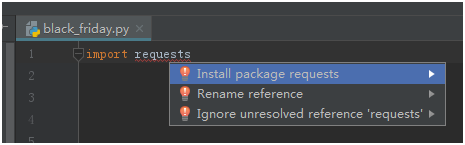
光标停留在有红底波浪线的requests上按「Alt」+「Enter」然后选择「Install package requests」等待模块安装完成后红色波浪线会消失。
以同样的方式安装「bs4」模块。
url = 'https://www.amazon.com/s/keywords=iphone'
response = requests.get(url)
二、拿到数据
「response」是一个变量名,用来保存目标网站返回给我们的数据。
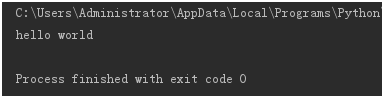
可使用下面代码在控制台打印出目标网站返回的数据。
print(response.text) 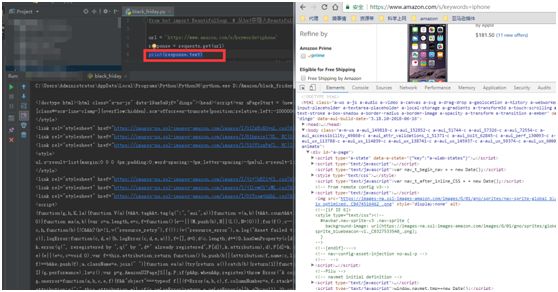
三、解析数据
返回的数据看起来乱七八糟的怎么办?这么大一堆怎么找到想要的数据呢?这就要用到刚才导入的「bs4」模块了。Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,Beautiful Soup会帮你节省数小时甚至数天的工作时间。
首先生成一个「BeautifulSoup」对象,我们命名为:response_soup:
response_soup = BeautifulSoup(response.text, 'html.parser')
其中「response.text」表示返回的数据,「html.parser」表示解析的方式。
result_list = response_soup.find('ul', id='s-results-list-atf').find_all("li")
在response_soup中找到id为s-results-list-atf的<ul>标签, 再在其中寻找所有的<li>标签。
for li in result_list:
print(li)
print("=" * 60)
可以用遍历的方式打印每个<li>标签,看是否与我们想要的数据一致。
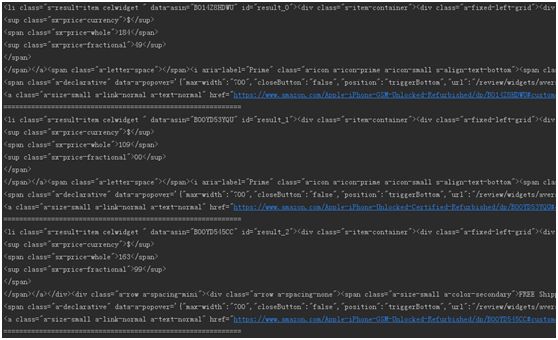
1、ASIN
配合Chrome我们可以看出每个<li>标签的“data-asin”即为商品的「ASIN」。
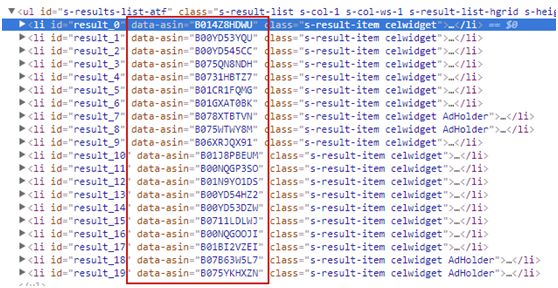
asin = li['data-asin'] 这样即可取出每件商品的「ASIN」。
2、Price

商品的价格是写在一个class为a-size-base a-color-base的<span>标签中。找出该标签,取出标签中的文本即可找出价格。
price = li.find('span', 'a-size-base a-color-base').text 3、Star
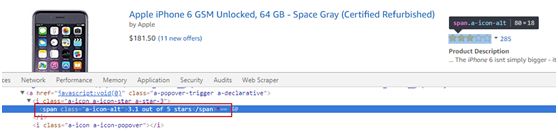
商品的star是写在一个class为a-icon-alt的<span>标签中。找出该标签,取出标签中的文本即可找出价格。
star = li.find('span','a-icon-alt').text 这样我们便爬到了一页中所有产品的Asin、Price、Star。
四、保存数据
使用csv库,将爬到的数据以csv格式保存下来。
import csv # 导入csv库 定义一个列表,用来保存每件商品的数据。
info_list = [] 将Asin、Price、Star添加到列表中。
info_list.append(asin)
info_list.append(price)
info_list.append(star)
打开csv文件(若当前路径下没有改文件,将自动创建)。这里命名csv文件为“iPhone.csv”
csvFile = open('./iphone.csv', 'a', newline='')
创建写入对象、写入数据并关闭csv文件。
writer = csv.writer(csvFile)
writer.writerow(info_list)
csvFile.close() 完整代码:
import requests # 导入requests
from bs4 import BeautifulSoup # 从bs4中导入BeautifulSoup
import csv
url = 'https://www.amazon.com/s/keywords=iphone'
response = requests.get(url)
response_soup = BeautifulSoup(response.text, 'html.parser')
result_list = response_soup.find('ul', id='s-results-list-atf').find_all("li")
for li in result_list:
info_list = []
try:
price = li.find('span', 'a-offscreen').text
except:
price = li.find('span', 'a-size-base a-color-base').text
asin = li['data-asin']
star = li.find('span', 'a-icon-alt').text
print(asin)
print(price)
print(star)
info_list.append(asin)
info_list.append(price)
info_list.append(star)
csvFile = open('./iphone.csv', 'a', newline='')
writer = csv.writer(csvFile)
writer.writerow(info_list)
csvFile.close()
print("=" * 60) 运行效果:
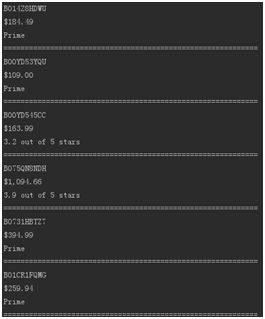
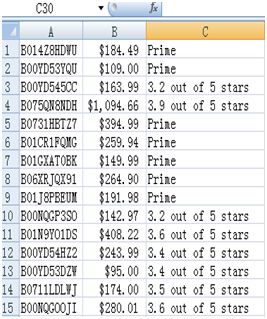

以上就是本期的爬虫文章,谢谢阅读。
附 「Requests」&「bs4」的中文操作文档:
Requests:
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
bs4:
http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/




{{comment.user.nickName}} (楼主)
{{comment.time}} 回复({{comment.childAmount}}) 点赞({{comment.voteUpAmount}}) 点赞({{comment.voteUpAmount}})